
Clustering Methods for Big Data Analytics: A Comprehensive Guide to Identifying Patterns and Groups

With the exponential growth of data in today's digital age, organizations are facing an unprecedented challenge in extracting meaningful insights from vast and complex datasets known as Big Data. Clustering methods have emerged as a powerful tool for Big Data analytics, enabling data analysts and scientists to uncover hidden patterns and group similar data points together.
What is Clustering?
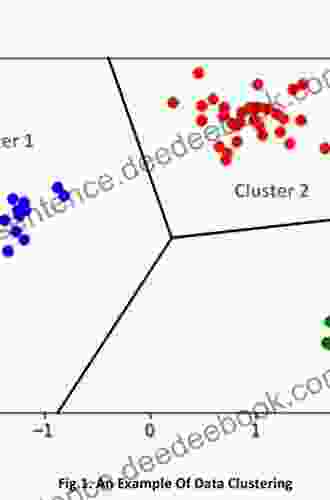
Clustering is a data mining technique used to group similar data points into distinct clusters. The objective is to identify natural groupings within the data based on their characteristics and relationships, thereby gaining a better understanding of the data's underlying structure. Clustering can be supervised or unsupervised, depending on whether prior knowledge about the data is available.
5 out of 5
| Language | : | English |
| File size | : | 17589 KB |
| Text-to-Speech | : | Enabled |
| Screen Reader | : | Supported |
| Enhanced typesetting | : | Enabled |
| Print length | : | 202 pages |
Types of Clustering Methods
There are numerous clustering methods available, each with its own advantages and disadvantages. Some common types of clustering methods include:
1. Hierarchical Clustering
Hierarchical clustering involves building a hierarchical tree-like structure that represents the relationships between data points. Starting with individual data points, this method iteratively merges similar clusters into larger clusters until a single cluster containing all data points is formed. Hierarchical clustering algorithms include:
* Single Link: Clusters data points based on the minimum distance between any two points in the clusters. * Complete Link: Clusters data points based on the maximum distance between any two points in the clusters. * Average Link: Clusters data points based on the average distance between all pairs of points in the clusters. * Ward's Method: Clusters data points based on the minimum increase in variance when merging two clusters.
2. Partitioning Clustering
Partitioning clustering assigns data points to a fixed number of pre-defined clusters. The goal is to minimize the within-cluster sum of squared errors (SSE),which measures the distance between data points and their assigned cluster centroid. Partitioning clustering algorithms include:
* K-Means: A widely used algorithm that partitions data into K clusters, where K is specified by the user. It iteratively assigns data points to the nearest cluster centroid, updates the cluster centroids, and repeats until convergence. * K-Meds: Similar to K-Means, but it uses meds (representative data points) instead of centroids to represent the clusters. This is less sensitive to outliers. * CLARANS: A hierarchical clustering algorithm that iteratively selects a med and assigns nearby data points to the cluster. It is efficient for large datasets.
3. Density-Based Clustering
Density-based clustering identifies clusters as dense regions of data points in the dataset. It does not assume a specific shape for the clusters and is able to handle clusters of arbitrary shapes and sizes. Density-based clustering algorithms include:
* DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Identifies clusters based on the density of data points in a neighborhood of a given radius. It can also identify noise points (outliers). * OPTICS (Ordering Points To Identify the Clustering Structure): Constructs a reachability graph to identify clusters based on the density and ordering of data points.
4. Model-Based Clustering
Model-based clustering assumes that the data follows a specific statistical model and tries to estimate the model parameters that best fit the data. Model-based clustering algorithms include:
* Gaussian Mixture Model (GMM): Assumes that the data is a mixture of Gaussian distributions. The algorithm estimates the parameters of the GMM to determine the clusters. * Bayesian Clustering: Uses Bayesian inference to estimate the cluster assignments and model parameters. It can handle uncertainty in the data.
Selection of Clustering Method
The choice of clustering method depends on factors such as the size and complexity of the dataset, the desired cluster shapes, and the availability of prior knowledge about the data. Hierarchical clustering is suitable for exploratory data analysis and identifying hierarchical relationships. Partitioning clustering is efficient for large datasets and well-defined clusters. Density-based clustering is suitable for finding clusters of arbitrary shapes and sizes. Model-based clustering assumes a statistical model and can provide more interpretable results.
Applications of Clustering in Big Data Analytics
Clustering methods have wide-ranging applications in Big Data analytics, including:
* Customer Segmentation: Identifying customer groups based on demographics, behavior, and preferences. * Image Segmentation: Breaking down an image into regions with similar characteristics. * Anomaly Detection: Identifying data points that deviate significantly from the normal behavior. * Recommendation Systems: Recommending items to users based on their preferences. * Predictive Modeling: Identifying patterns and creating predictive models to forecast future events.
Challenges in Clustering Big Data
Clustering Big Data presents unique challenges due to its volume, variety, and velocity:
* Volume: Massive datasets can overwhelm clustering algorithms and slow down the processing time. * Variety: Heterogeneous data types and formats can make it difficult to compare and cluster data points. * Velocity: Streaming data requires real-time or near real-time clustering algorithms.
Big Data Clustering Tools
Several tools and frameworks are available to perform clustering on Big Data, including:
* Apache Spark MLlib: A scalable machine learning library that supports various clustering algorithms for distributed data processing. * Scikit-learn: A Python library that provides implementations of several clustering algorithms for both small and large datasets. * H2O.ai: A platform for machine learning and AI, offering a range of clustering algorithms optimized for Big Data. * Google Cloud Machine Learning Engine: A managed service for training and deploying machine learning models, including clustering algorithms.
Clustering methods are essential tools for Big Data analytics, enabling data analysts and scientists to uncover hidden patterns, group similar data points, and gain valuable insights from complex datasets. By understanding the different types of clustering methods, their strengths and limitations, and the challenges in clustering Big Data, organizations can effectively leverage this technique to drive data-driven decisions and improve business outcomes.
5 out of 5
| Language | : | English |
| File size | : | 17589 KB |
| Text-to-Speech | : | Enabled |
| Screen Reader | : | Supported |
| Enhanced typesetting | : | Enabled |
| Print length | : | 202 pages |
Do you want to contribute by writing guest posts on this blog?
Please contact us and send us a resume of previous articles that you have written.
 Novel
Novel Chapter
Chapter Text
Text Story
Story Reader
Reader Paperback
Paperback E-book
E-book Newspaper
Newspaper Paragraph
Paragraph Sentence
Sentence Bookmark
Bookmark Shelf
Shelf Glossary
Glossary Preface
Preface Synopsis
Synopsis Annotation
Annotation Footnote
Footnote Codex
Codex Tome
Tome Library card
Library card Narrative
Narrative Autobiography
Autobiography Reference
Reference Encyclopedia
Encyclopedia Dictionary
Dictionary Thesaurus
Thesaurus Narrator
Narrator Resolution
Resolution Card Catalog
Card Catalog Stacks
Stacks Archives
Archives Research
Research Academic
Academic Interlibrary
Interlibrary Literacy
Literacy Study Group
Study Group Storytelling
Storytelling Reading List
Reading List Book Club
Book Club Textbooks
Textbooks Erica Ekrem
Erica Ekrem Geoffrey Chaucer
Geoffrey Chaucer Callie Cardamon
Callie Cardamon Jason Heard
Jason Heard Jeff Altgilbers
Jeff Altgilbers Keiji Sano
Keiji Sano Jefferson Bryant
Jefferson Bryant Tiffany Reisz
Tiffany Reisz Tammy Gagne
Tammy Gagne Emily Belden
Emily Belden Francis Srun
Francis Srun Julian Pancho S Garcia
Julian Pancho S Garcia Jackson Streit
Jackson Streit Dayle Campbell Gaetz
Dayle Campbell Gaetz Keir Graff
Keir Graff Dave Armstrong
Dave Armstrong Ardy Reed
Ardy Reed Kyle Campbell Miller
Kyle Campbell Miller Caitlin Major
Caitlin Major Dave Chaffey
Dave Chaffey
Light bulbAdvertise smarter! Our strategic ad space ensures maximum exposure. Reserve your spot today!










 Ryūnosuke AkutagawaFollow ·14.9k
Ryūnosuke AkutagawaFollow ·14.9k Harry HayesFollow ·14.9k
Harry HayesFollow ·14.9k Kevin TurnerFollow ·8.2k
Kevin TurnerFollow ·8.2k Travis FosterFollow ·4.9k
Travis FosterFollow ·4.9k Julian PowellFollow ·17.4k
Julian PowellFollow ·17.4k Miguel NelsonFollow ·19.6k
Miguel NelsonFollow ·19.6k Rodney ParkerFollow ·10.8k
Rodney ParkerFollow ·10.8k Deacon BellFollow ·19.7k
Deacon BellFollow ·19.7k

 Darren Nelson
Darren NelsonLife of Napoleon Bonaparte, Volume II: His Rise to Power
**** Napoleon...

 Reed Mitchell
Reed MitchellLucy Sullivan Is Getting Married: A Tale of Love,...
Lucy Sullivan is a...

 Chuck Mitchell
Chuck MitchellBeginner's Crash Course on Python Language: Getting...
Python is a widely used programming...

 Henry Hayes
Henry HayesThreads Fitting For Every Figure: A Comprehensive Guide...
Finding the perfect fit can be a...

 Duane Kelly
Duane KellyA Comprehensive Cat Guide to Money: Feline Finance for...
In the world of finance, humans have...

 Jedidiah Hayes
Jedidiah HayesThe Sentimental Hippo And His Friends
Harvey the hippo was a very sentimental...
5 out of 5
| Language | : | English |
| File size | : | 17589 KB |
| Text-to-Speech | : | Enabled |
| Screen Reader | : | Supported |
| Enhanced typesetting | : | Enabled |
| Print length | : | 202 pages |
